
We just hit a milestone that made us stop and reflect.
Three years ago, we made an audacious bet: that you can treat automated chemistry as a learning problem — and solve it by scaling chemical data generation.
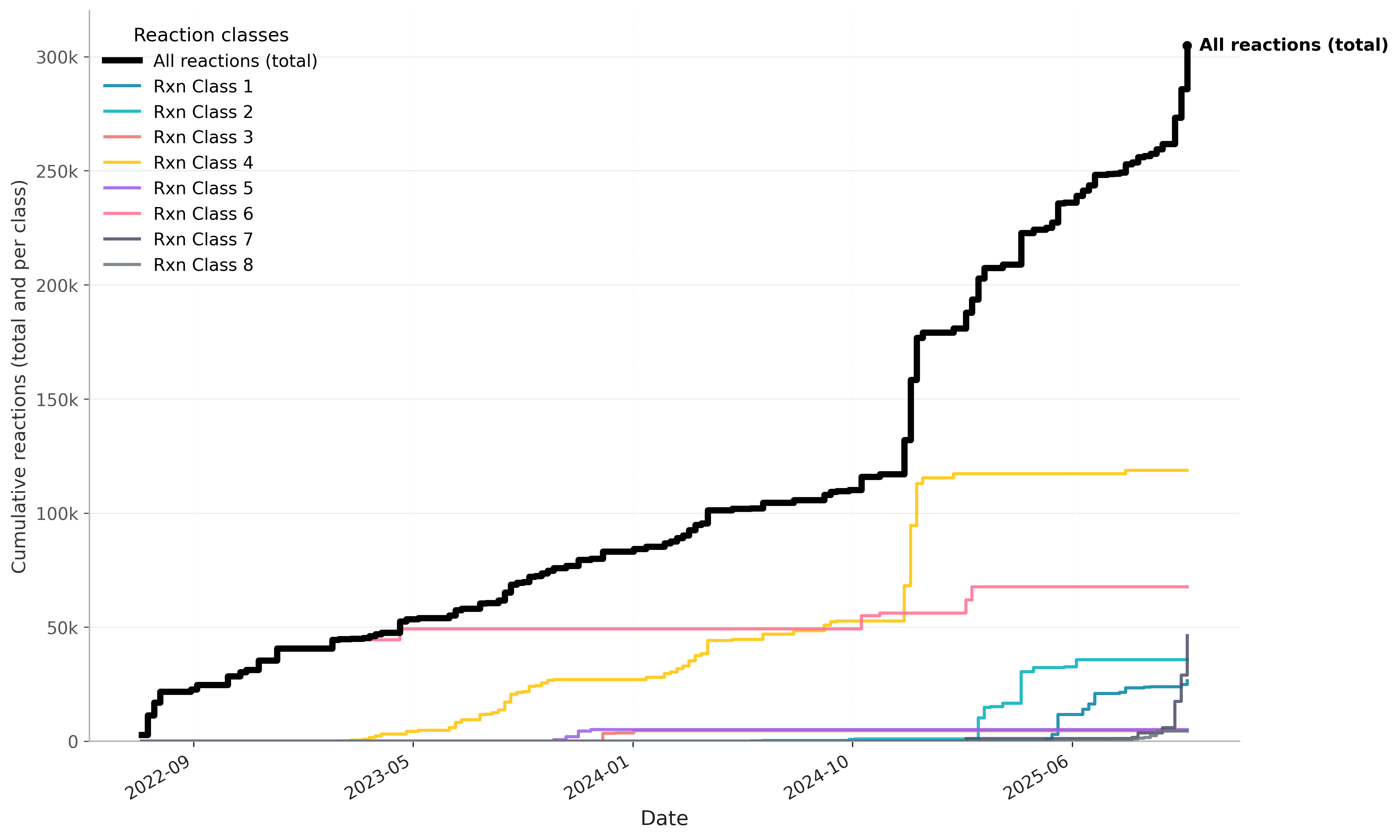
Fast forward to today: we're running what is (likely) one of the largest sustained microliter-scale data generation efforts on the planet. Our lab has been running 12,000 reactions per week for the last month, and has executed over 200,000 microliter-scale reactions in the past 12 months.
Most importantly: the bet was right.
But this post isn't just about numbers. It's about how building that data engine reshaped our company.
We dedicate this blog post to the amazing team behind this project.
The Hard Problem of Chemistry: Why Self-Driving Labs are Not Here Despite Promises
We founded the company based on our deep dissatisfaction with molecule synthesis.
Drug discovery is held back by too slow and too expensive small molecule synthesis:
- CRO costs keep rising due to FTE-based (not outcome-based) pricing.
- Compounds from on-demand spaces offer limited diversity.
- In-house synthesis simply isn't a scalable solution.
The most interesting question is why is it the case?
At the core is unpredictability. As chemists like to say: 'chem-is-try.' Even expert chemists miss — a lot. Reaction failure rates are high across published studies, and most conditions don't transfer cleanly from paper to reality. This forces per-FTE pricing (not per-success) or pushes teams toward less diverse chemistry.
This issue fundamentally limits automatization of chemistry and explains why self-driving labs are not around despite over a decade of promises. Just like in self-driving cars: the bottleneck isn't the robot — it's the decision-making 'brain'.
We call this the Hard Problem of Chemistry: building a highly robust model of all chemical reactivity.
Our Bet: Scaling Laws using Microliter Chemistry
The unsung hero of protein folding is Protein Data Bank (PDB). Without PDB, there would be no AlphaFold, and in our view PDB authors should receive a Nobel Prize in the future.
There is no equivalent of PDB in synthetic chemistry. Public reaction data that everyone trains on comes from literature, which is extremely biased (who would publish a failed reaction?) and doesn't allow for training generalizing models.
Our inspiration has come from deep learning. Ilya Sutskever, pioneer in deep learning and co-founder of OpenAI, has made once this now famous slide:
We made an audacious bet that we can turn chemistry from art into engineering by scaling data generation.
What we were unsure about: can the models generalize to broad enough chemical space such that it allows meaningful and cheap automation of synthesis?
Strategically, we decided to build a capital intensive lab focused on microliter chemistry and commodity robots. That is, we primarily perform reactions in 96 well plates in 10-100µL volume, using simple robotics.
These choices let us run ~10× more reactions at the same budget than comparable efforts.
Crucially, we decided to cover a 100x wider (than HTE studies at the time) range diversity of building blocks. We use only a few sets of conditions that jointly achieve a high success rate.
We thought that only then would we succeed at training generalizing models. But it also led to significant challenges.
The Challenges: Surprising Obstacles Coming from Pioneering Work
As our chemist, Aleksander Szkółka, reflects:
"we routinely set up more reactions in a single day than I've set up over a 5-year period".
High-throughput experimentation (HTE) existed in other academic and commercial settings, but not at this diversity of different products and number of reactions.
We hit a surprising roadblock with processing the analytical results of our experiments. We primarily use liquid chromatography-UV-mass spectrometry. We assumed that we could simply use existing software. But because essentially no one was analyzing microliter-scale reactions generating novel products at this diversity, solutions on the market were not able to accurately handle it.
How did we solve it? We trained custom models to annotate peaks and estimate reaction yields. As far as we know, this is still novel on the market, and more accurate.
This was a repeating theme. We kept hitting 'first-of-its-kind' obstacles—and built custom models, laboratory equipment, and data pipelines to clear them.
The Remarkable Campaign Run by a Startup
Fast-forward to today, we are performing what is likely the largest reaction campaign on the planet.
We have run 300,000+ microliter reactions and are now operating at 12,000 reactions a week. Figure 1 summarizes our progress over the last three years.
Looking at the number of reactions is just one aspect. The campaign is remarkable on many fronts:
- Using custom software for analytics that is based on machine learning and quantum calculations;
- Achieving >100x larger product diversity than most datasets published;
- Achieving all of the above using commoditized or hacked by us laboratory hardware (e.g. Opentrons).
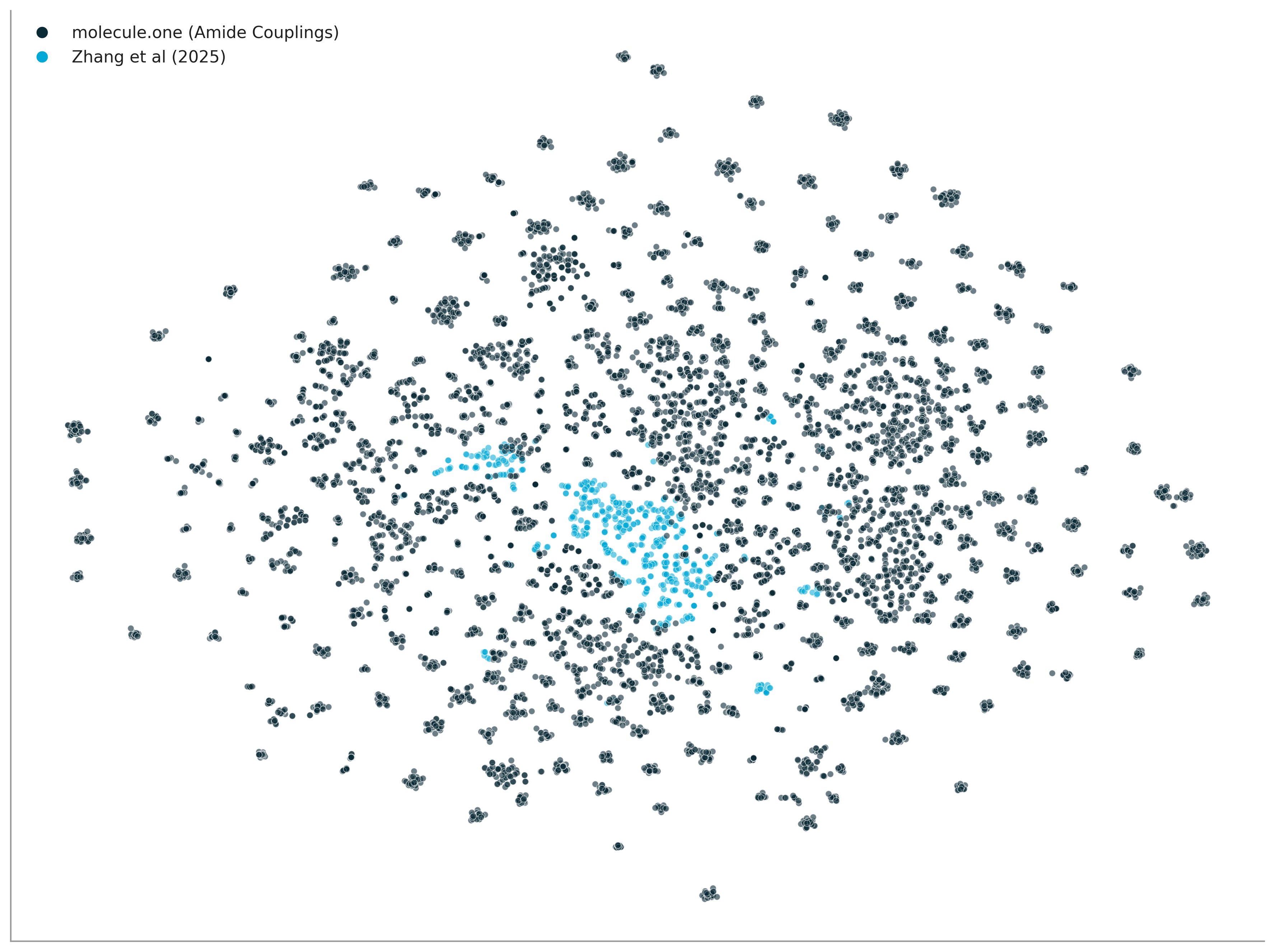
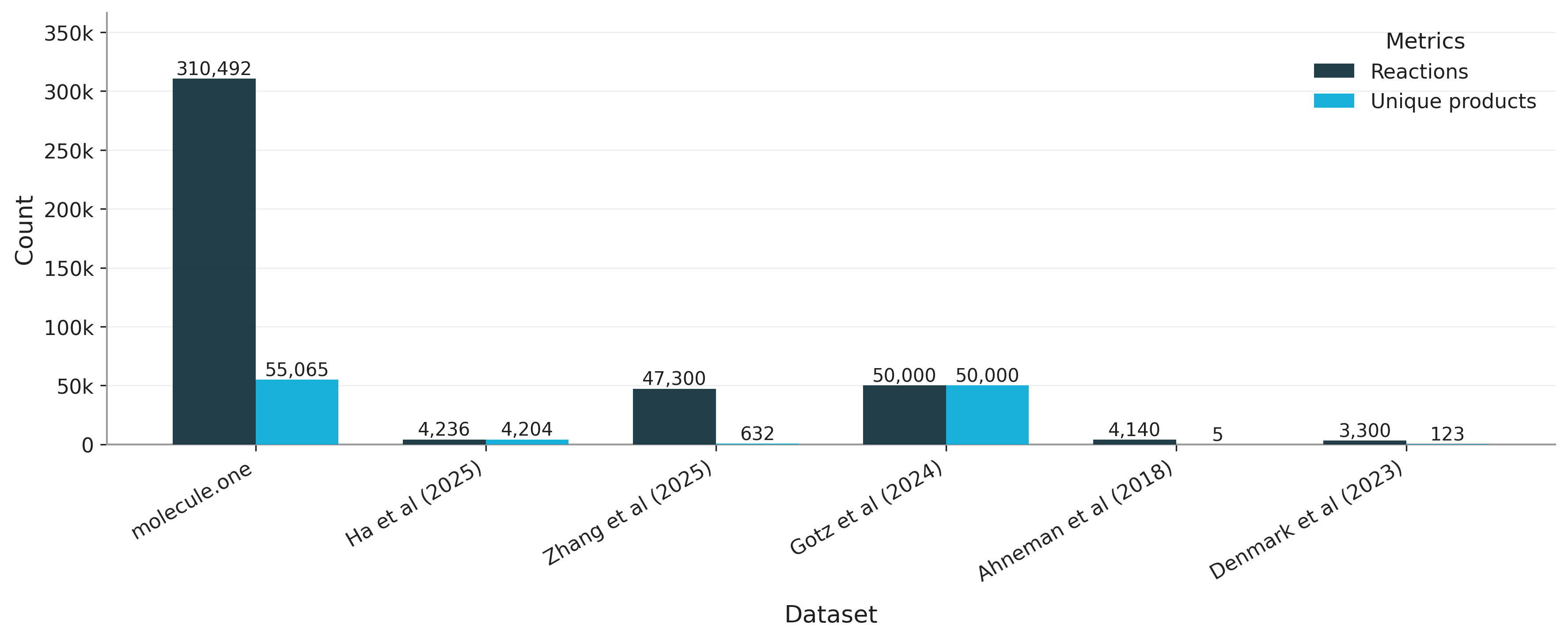
Let's zoom in on product diversity. Figure 3 illustrates the leading diversity of our amide coupling space in comparison with a recent screen from Zhang et al (2025). We also compare to other datasets in Figure 4.
Deeply Meaningful Moment: Discovering Superhuman Reactivity Patterns
Our main bet was that by scaling reaction generation we can start to understand broad reactivity patterns.
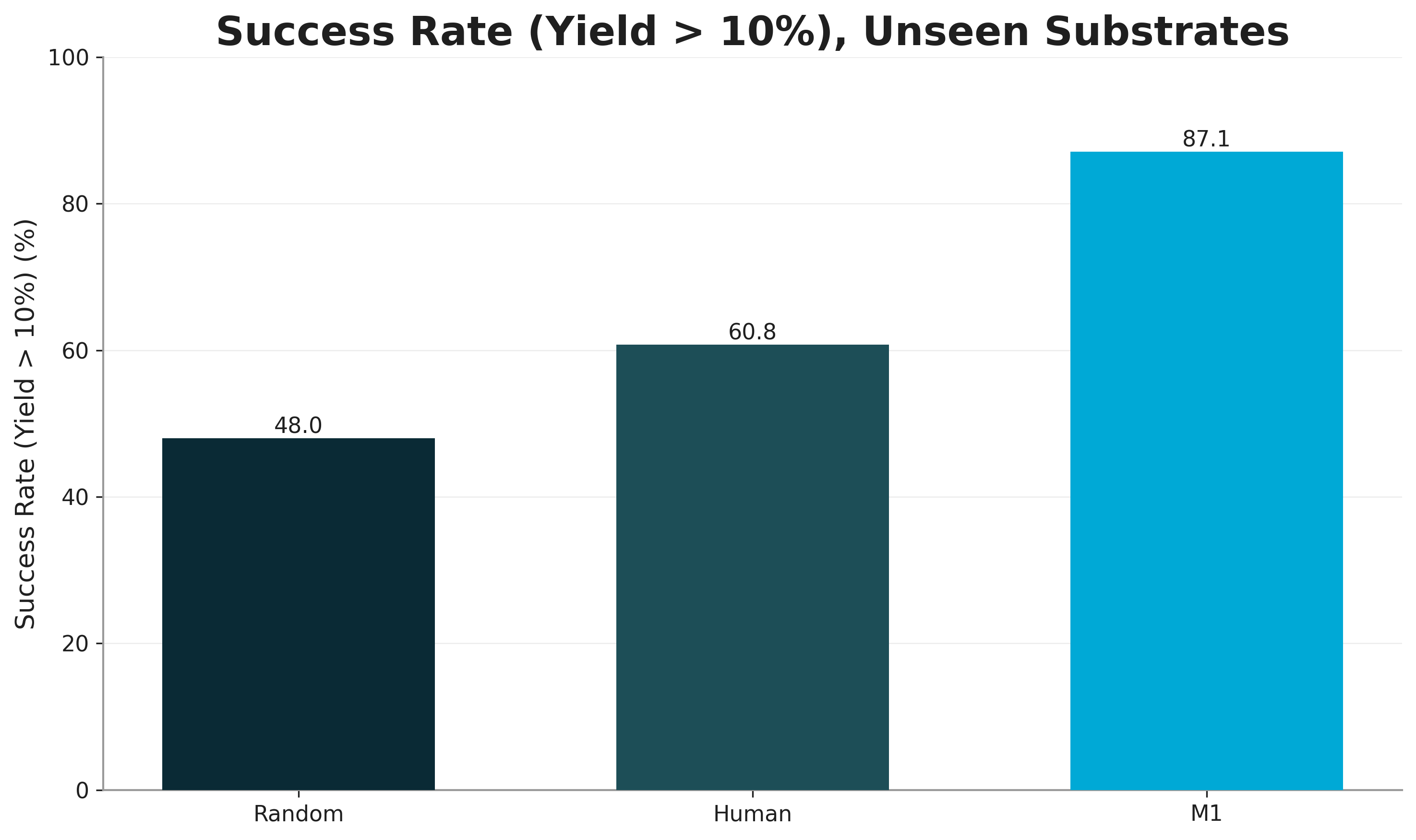
Last year we ran the following experiment. We asked three PhD level organic chemists to predict whether a set of 100 Suzuki Couplings would achieve >10% (LC-MS) yield. We then evaluated how many did in fact succeed, in the top 50% most highly scored reactions. Figure 5 reports the result.
Crucial in the setup was that we measured broad generalization. We excluded from the training set any reactions that used any of the tested building blocks.
We see that while humans outperform random classification (60% vs 50%), our models achieve an impressive 87.1% success rate. Our models have clearly learned superhuman reactivity patterns.
This was a deeply meaningful moment for us; confirming the validity of a hypothesis after 2 years of work.
Please stay tuned for a separate blog about the technical aspects.
The Real Transformation: Making Molecules Ourselves
What came next changed the DNA of our company.
Following what we saw in the human comparison, we made the call that the best way we can bring value from those models to our customers, is by directly making molecules.
In the first big project, we achieved a 90% success rate in library synthesis for a leading biotech company, for reactions planned by models trained only on our data.
Retrospective tests like the one shared in the previous section is one thing. Seeing real bench chemistry impact is another. As Paulina Wach, our Head of Chemistry, said:
"This moment was when I realized that we can change chemistry with HTE, and that molecule.one will never be the same."
The photo shows Paulina, next from 384 plates illustrating a campaign that we ran earlier this year.

Vision Ahead: Going Beyond Human Chemistry
For us, this isn't the end of the story — it's the first chapter of how chemistry is about to change.
What's remarkable is that we have built a repeatable process to learn chemistry from data: without any hand-coded human knowledge.
Next: apply the same blueprint to discover a novel reaction class. Suzuki Coupling – a Nobel prize winning reaction class – has redefined drug discovery. We believe the next reaction class of this impact will come from AI-first workflows.
For partners, the impact of our work is access to differentiated molecular space, supported by models that go beyond human chemical intuition.
We are extremely excited about what's next. And we are just getting started.